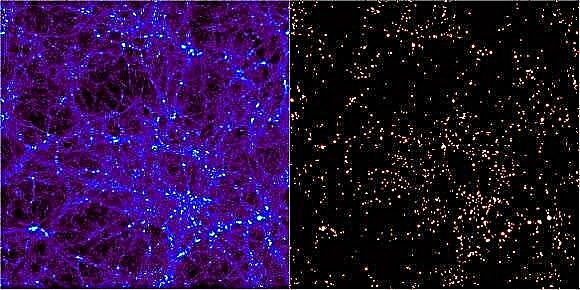
Jedním z úspěchů modelu ΛCDM vesmíru je schopnost modelů vytvářet struktury s měřítky a distribucemi podobnými těm, které vidíme v časopise Space Magazine. Zatímco počítačové simulace mohou znovu vytvořit numerické vesmíry v krabici, interpretace těchto matematických aproximací je sama o sobě výzvou. Aby astronomové mohli identifikovat komponenty simulovaného prostoru, museli vyvinout nástroje pro hledání struktury. Výsledky jsou od roku 1974 téměř 30 nezávislých počítačových programů. Každý slibuje odhalit formující strukturu ve vesmíru nalezením oblastí, ve kterých se tvoří halos temné hmoty. Pro testování těchto algoritmů byla v květnu 2010 uspořádána konference v Madridu ve Španělsku s názvem „Haloes going MAD“, ve které bylo 18 z těchto kódů testováno, aby se zjistilo, jak dobře se nashromáždily.
Numerické simulace pro vesmír, jako je slavná simulace Millennium Simulation, nezačíná nic jiného než „částice“. Zatímco tyto byly nepochybně malé v kosmologickém měřítku, takové částice představují skvrny temné hmoty s miliony nebo miliardami solárních hmot. Jak běží čas dopředu, mohou se navzájem ovlivňovat podle pravidel, která se shodují s naším nejlepším porozuměním fyzice a povaze takové hmoty. To vede k vyvíjejícímu se vesmíru, z něhož musí astronomové používat složité kódy k nalezení konglomerací temné hmoty uvnitř galaxií.
Jednou z hlavních metod, které tyto programy používají, je hledání malých nadměrných hodnot a potom kolem ní naroste sférická skořápka, dokud hustota neklesne na zanedbatelný faktor. Většina z nich pak prořízne částice v objemu, které nejsou gravitačně vázány, aby se ujistil, že detekční mechanismus se nezachytil jen na krátkém, přechodném shlukování, které se časem rozpadne. Jiné techniky zahrnují hledání dalších fázových prostorů pro částice s podobnými rychlostmi všude v okolí (znamení, že se staly vázány).
Aby bylo možné porovnat, jak se jednotlivé algoritmy daří, byly podrobeny dvěma testům. První z nich zahrnoval řadu záměrně vytvořených halos temné hmoty s vloženými podsvětly. Protože distribuce částic byla záměrně umístěna, výstup z programů by měl správně najít střed a velikost halo. Druhým testem byla plnohodnotná simulace vesmíru. V tomto případě by skutečná distribuce nebyla známa, ale její velikost by umožnila porovnat různé programy na stejném datovém souboru a zjistit, jak podobně interpretují společný zdroj.
V obou testech měli všichni nálezci obecně dobrý výkon. V prvním testu byly některé nesrovnalosti založené na tom, jak různé programy definovaly umístění halos. Někteří to definovali jako vrchol hustoty, zatímco jiní to definovali jako centrum hmoty. Při hledání subhalogenů se zdálo, že ty, které využívaly přístup fázového prostoru, dokázaly spolehlivěji detekovat menší formace, ale ne vždy detekovaly, které částice ve shluku byly skutečně vázány. Pro úplnou simulaci se všechny algoritmy dohodly výjimečně dobře. Vzhledem k povaze simulace nebyly malé měřítka dobře zastoupeny, takže chápání toho, jak každá z nich detekuje tyto struktury, bylo omezené.
Kombinace těchto testů neupřednostňovala jeden konkrétní algoritmus nebo metodu před ostatními. Ukázalo se, že každý obecně funguje dobře ve vztahu k sobě navzájem. Schopnost tolika nezávislých kódů s nezávislými metodami znamená, že zjištění jsou extrémně robustní. Znalosti, které předávají o tom, jak se naše chápání vesmíru vyvíjí, umožňují astronomům provést základní srovnání s pozorovatelným vesmírem, aby mohli vyzkoušet tyto modely a teorie.
Výsledky tohoto testu byly shrnuty do článku, který je navržen pro zveřejnění v nadcházejícím vydání Měsíčních oznámení Královské astronomické společnosti.